Agent Learns to do Reinforcement Learning
Video Not Working? Fix It Now
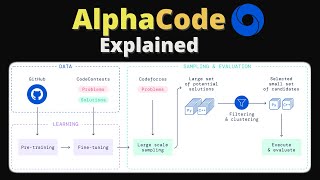
"In-context Reinforcement Learning with Algorithm Distillation" is a new paper from DeepMind about learning how to learn how to do Reinforcement Learning (RL) using behavior cloning over a learning history with a Transformer. The idea is simple, but I think the implications could be big for the future.
Outline
0:00 - Intro
0:30 - Why I like this paper
2:08 - ClearML
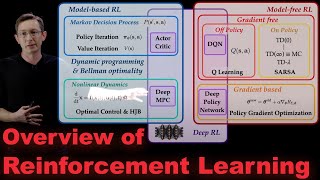
3:17 - Algorithm Overview
7:50 - Bandits
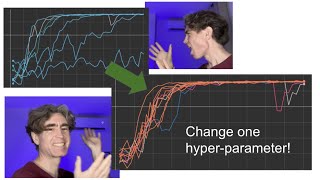
9:06 - Robustness Results
15:08 - Speedup Results
22:00 - Other Results
23:00 - Conclusion
ClearML - https://bit.ly/3GtCsj5
Social Media
YouTube - https://youtube.com/c/EdanMeyer
Twitter - https://twitter.com/ejmejm1
RL AD Paper - https://arxiv.org/abs/2210.14215
Comment