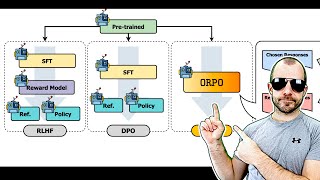
Combined Preference and Supervised Fine Tuning with ORPO
Video Not Working? Fix It Now
➡️ ADVANCED-fine-tuning Repo (incl. ORPO Scripts): https://trelis.com/advanced-fine-tuning-scripts/
➡️ One-click Fine-tuning, Evaluation & Inference Templates: https://github.com/TrelisResearch/one-click-llms/
➡️ ADVANCED-inference Repo: https://trelis.com/enterprise-server-api-and-inference-guide/
➡️ Trelis Function-calling Models: https://trelis.com/function-calling/
➡️ Trelis Newsletter: https://Trelis.Substack.com
➡️ Support/Discord (Monthly Subscription): https://ko-fi.com/trelisresearch
Affiliate Link (supports the channel):
- RunPod - https://tinyurl.com/4b6ecbbn
VIDEO RESOURCES:
- Slides: https://docs.google.com/presentation/d/1HJAwhiRSH0jXZou1Ergq16lyCJZfH7F6uRVxDWIimls/edit?usp=sharing
- Dataset: https://huggingface.co/datasets/argilla/dpo-mix-7k
- TinyLlama ORPO model: https://huggingface.co/Trelis/TinyLlama-chat-ORPO-beta0.2
- Mistral ORPO model: https://huggingface.co/Trelis/Mistral-7B-v0.1-chat-ORPO
- Evaluation: https://github.com/EleutherAI/lm-evaluation-harness
- TRL Documents: https://github.com/huggingface/trl
- ORPO Repo: https://github.com/xfactlab/orpo
TIMESTAMPS:
0:00 Preference and Supervised Fine-tuning at the Same Time!
0:25 A short history of fine-tuning methods
3:12 Video Overview/Agenda
3:43 Difference between Unsupervised, Supervised and Preferences
6:04 Understanding cross-entropy and odds ratio loss functions
10:26 Why preference fine-tuning improves performance
11:41 Notebook demo of SFT and ORPO
24:22 Evaluation with lm-evaluation-harness
26:38 Results: Comparing SFT and ORPO with gsm8k, arithmetic and mmlu
27:44 Evaluation with Carlini's practical benchmark
29:50 Is it worth doing ORPO? Yes!
Comment