End-To-End Data Engineering Project in AWS | Build complete Data Pipeline in AWS within 25 mins
Video Not Working? Fix It Now
Architecture template link - https://github.com/AnandDedha/AWS/blob/main/aws-etl/s3-glue-redshift-iam.yaml
Pyspark script link - https://github.com/AnandDedha/AWS/blob/main/aws-etl/s3-glue-redshift-iam.yaml
Data sample link - https://github.com/AnandDedha/AWS/blob/main/aws-etl/sales_records.csv
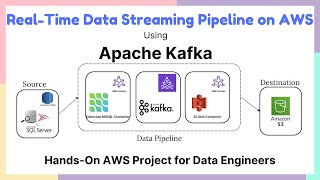
00:42 Data Engineering architecture in AWS
04:55 Data-pipeline using Pyspark in AWS
11:21 ETL code explanation
22:51 Summary
In this video, we'll learn about several important topics related to data engineering in AWS (Amazon Web Services).
We'll understand how to create a data engineering system in AWS using something called "Infrastructure as Code." This helps make the system scalable and easy to maintain.
We'll see how to build a data pipeline in PySpark using Glue Jupyter interactive notebooks. This involves reading data from an s3 storage, processing it in Spark, and then loading it into Redshift.
We'll explore two concepts: "Dynamic frames" and "Spark data frames," which are essential for data processing.
The video provides a step-by-step explanation of the code used in the ETL.
#aws
#awsdataengineer
#awsdataanalytics
#awsbigdata
#AWSDataEngineering
#awstraining
#awscloudpractitioner
#awsclouddataengineer
#awscloudformation
#pyspark
#awsglue
#awss3
#redshift
AWS Big Data
AWS Data Engineer
AWS Data Analytics
AWS
AWS Data Engineering
Data Engineering Architecture
AWS Glue
AWS Redshift
AWS S3
AWS Datapipeline
Email: datatechdemo2@gmail.com
Comment















![AWS Glue Tutorial for Beginners [NEW 2024 - FULL COURSE]](https://ytimg.googleusercontent.com/vi/ZvJSaioPYyo/mqdefault.jpg)
