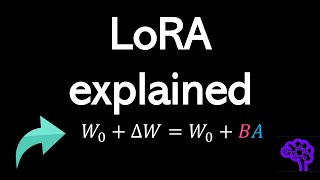Optimize Your AI - Quantization Explained
Video Not Working? Fix It Now
🚀 Run massive AI models on your laptop! Learn the secrets of LLM quantization and how q2, q4, and q8 settings in Ollama can save you hundreds in hardware costs while maintaining performance.
🎯 In this video, you'll learn:
• How to run 70B parameter AI models on basic hardware
• The simple truth about q2, q4, and q8 quantization
• Which settings are perfect for YOUR specific needs
• A brand new RAM-saving trick with context quantization
⏱️ Timestamps:
[00:00] Introduction & Quick Overview
[01:04] Why AI Models Need So Much Memory
[02:00] Understanding Quantization Basics
[03:20] K-Quants Explained
[04:20] Performance Comparisons
[04:40] Context Quantization Game-Changer
[05:20] Practical Demo & Memory Savings
[09:00] How to Choose the Right Model
[09:50] Quick Action Steps & Conclusion
🔗 Resources mentioned:
• Ollama: https://ollama.com
• Our Discord Community: https://discord.gg/uS4gJMCRH2
💡 Want more AI optimization tricks? Hit subscribe and the bell - next week's video will show you even more ways to maximize your AI performance!
#AIOptimization #Ollama #MachineLearning
My Links 🔗
👉🏻 Subscribe (free): https://www.youtube.com/technovangelist
👉🏻 Join and Support: https://www.youtube.com/channel/UCHaF9kM2wn8C3CLRwLkC2GQ/join
👉🏻 Newsletter: https://technovangelist.substack.com/subscribe
👉🏻 Twitter: https://www.twitter.com/technovangelist
👉🏻 Discord: https://discord.gg/uS4gJMCRH2
👉🏻 Patreon: https://patreon.com/technovangelist
👉🏻 Instagram: https://www.instagram.com/technovangelist/
👉🏻 Threads: https://www.threads.net/@technovangelist?xmt=AQGzoMzVWwEq8qrkEGV8xEpbZ1FIcTl8Dhx9VpF1bkSBQp4
👉🏻 LinkedIn: https://www.linkedin.com/in/technovangelist/
👉🏻 All Source Code: https://github.com/technovangelist/videoprojects
Want to sponsor this channel? Let me know what your plans are here: https://www.technovangelist.com/sponsor
Comment