[Paper Reading] Token Former: Rethinking Transformer Scaling with Tokenized Model Parameters
Video Not Working? Fix It Now
Speaker: Asif Qamar [https://www.linkedin.com/in/asifqamar/]
SupportVectors AI Training Lab [https://supportvectors.ai]
As part of our weekly paper reading, we are going to cover the paper titled "Token Former: Rethinking Transformer Scaling with Tokenized Model Parameters"
Here are a few key points from the paper reading session:
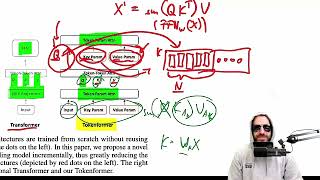
-Efficient Transformer Scaling: The Token Forer introduces a new architecture for transformer scaling, using tokenized parameters instead of increasing model size from scratch, significantly reducing the compute cost of scaling models.
-Innovative P-Attention Mechanism: The authors propose the P-attention mechanism, which replaces linear projection layers and feedforward networks. This enables the model to grow by adding new key-value pairs, allowing scalable and incremental learning.
-Mitigating Vanishing Gradients: The use of GELU activation in the attention mechanism reduces the likelihood of vanishing gradients by avoiding softmax’s tendency to zero out gradients, supporting more stable learning across layers.
-Modular Growth with Minimal Compute: The Token Forer architecture allows for modular expansion, similar to Mixture of Experts models, where additional tokens specialize in specific tasks, enhancing generalization without extensive retraining.
-Potential Breakthrough in AI Accessibility: This method reduces compute demands, potentially democratizing access to high-performance model scaling, enabling research beyond resource-heavy institutions and facilitating broader AI innovation.
Comment

![[Paper Reading] RouteLLM: Learning to Route LLMs with Preference Data](https://ytimg.googleusercontent.com/vi/J4A7YgUh-AM/mqdefault.jpg)















![[Paper Reading] LLM Post-Training: A Deep Dive into Reasoning LLMs](https://ytimg.googleusercontent.com/vi/CLZEJeszyX8/mqdefault.jpg)
![[Paper Reading] Advancing Semantic Caching for LLMs with Domain-Specific Embeddings & Synthetic Data](https://ytimg.googleusercontent.com/vi/oqkfo4QnTUQ/mqdefault.jpg)