Self Attention in Transformers | Deep Learning | Simple Explanation with Code!
Video Not Working? Fix It Now
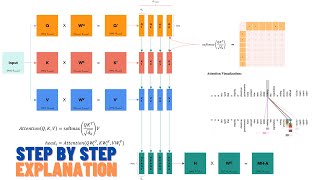
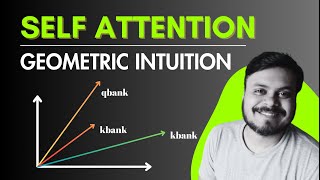
Self Attention works by computing attention scores for each word in a sequence based on its relationship with every other word. These scores determine how much focus each word receives during processing, allowing the model to prioritize relevant information and capture complex dependencies across the sequence.
Digital Notes for Deep Learning: https://shorturl.at/NGtXg
============================
Do you want to learn from me?
Check my affordable mentorship program at : https://learnwith.campusx.in/s/store
============================
📱 Grow with us:
CampusX' LinkedIn: https://www.linkedin.com/company/campusx-official
CampusX on Instagram for daily tips: https://www.instagram.com/campusx.official
My LinkedIn: https://www.linkedin.com/in/nitish-singh-03412789
Discord: https://discord.gg/PsWu8R87Z8
E-mail us at support@campusx.in
✨ Hashtags✨
#SelfAttention #DeepLearning #CampusX #Transformers #NLP #GENAI
⌚Time Stamps⌚
00:00 - Intro
02:37 - Revision [What is Self Attention]
07:00 - How does Self Attention work?
24:45 - Parallel Operations
29:40 - No Learning Parameters Involved
39:10 - Progress Summarization
50:15 - Query, Key & Value Vectors
52:28 - A Relatable Example
01:07:52 - How to build vectors based on Embedding vector
01:20:08 - Summarized Matrix Attention
01:22:45 - Outro
Comment