Vision Transformer Basics
Video Not Working? Fix It Now
An introduction to the use of transformers in Computer vision.
Timestamps:
00:00 - Vision Transformer Basics
01:06 - Why Care about Neural Network Architectures?
02:40 - Attention is all you need
03:56 - What is a Transformer?
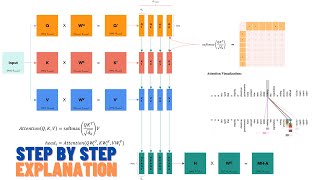
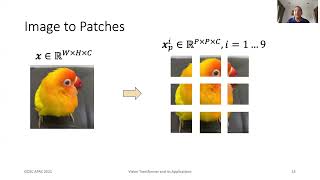
05:16 - ViT: Vision Transformer (Encoder-Only)
06:50 - Transformer Encoder
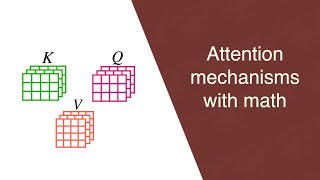
08:04 - Single-Head Attention
11:45 - Multi-Head Attention
13:36 - Multi-Layer Perceptron
14:45 - Residual Connections
16:31 - LayerNorm
18:14 - Position Embeddings
20:25 - Cross/Causal Attention
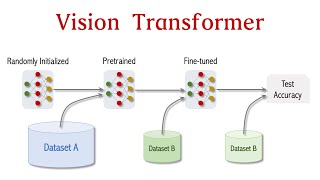
22:14 - Scaling Up
23:03 - Scaling Up Further
23:34 - What factors are enabling effective further scaling?
24:29 - The importance of scale
26:04 - Transformer scaling laws for natural language
27:00 - Transformer scaling laws for natural language (cont.)
27:54 - Scaling Vision Transformer
29:44 - Vision Transformer and Learned Locality
Topics: #computervision #ai #introduction
Notes:
This lecture was given as part of the 2022/2023 4F12 course at the University of Cambridge.
It is an update to a previous lecture, which can be found here: https://www.youtube.com/watch?app=desktop&v=FyM0rYUvFbM
Links:
Slides (pdf): https://samuelalbanie.com/files/digest-slides/2023-11-vision-transformer-basics.pdf
References for papers mentioned in the video can be found at
http://samuelalbanie.com/digests/2023-11-vision-transformer-basics
For related content:
- Twitter: https://twitter.com/SamuelAlbanie
- personal webpage: https://samuelalbanie.com/
- YouTube: https://www.youtube.com/@SamuelAlbanie1
Comment